
The Hallucinations Edition
On AI, creativity, and what computers are and aren't good at

I shared this yesterday on my BrXnd newsletter and CJN, and I thought it was worthy of a WITI. It’s some really smart ideas from friend and WITI contributor Tim Hwang about AI and what it’s good at/not good at. - Noah
Noah here. Despite the noise, there’s still quite a bit of confusion around what’s going on with AI: what it’s good at, not good at, when it’s lying to you (“hallucinating”), and generally what to make of all this stuff. When I put on my BrXnd Marketing AI Conference in May, I knew I wanted to have Tim talk because he’s fantastic at disentangling things generally, particularly in AI/machine learning, a field he’s been working in for a decade or more.
WITI Classifieds:
We are experimenting with running some weekly classifieds in WITI. If you’re interested in running an ad, you can purchase one through this form.
Interpreting the internet for the tasteful reader. Join 23,000+ subscribers who rely on Dirt for their cultural alpha. Subscribe for free
Why Are Formats Interesting? Join Storythings & The Content Technologist to find out how to make great B2B formats, in NYC on 26th Sept Book your place now!
To start, Tim did a great job explaining where hallucinations come from, but his point that large language models (LLMs) are bad at everything we expect a computer to be good at and good at everything we expect a computer to be bad at that really hit me. In fact, after his talk, I put together this little slide to help share with others because I thought he summarized things so nicely:
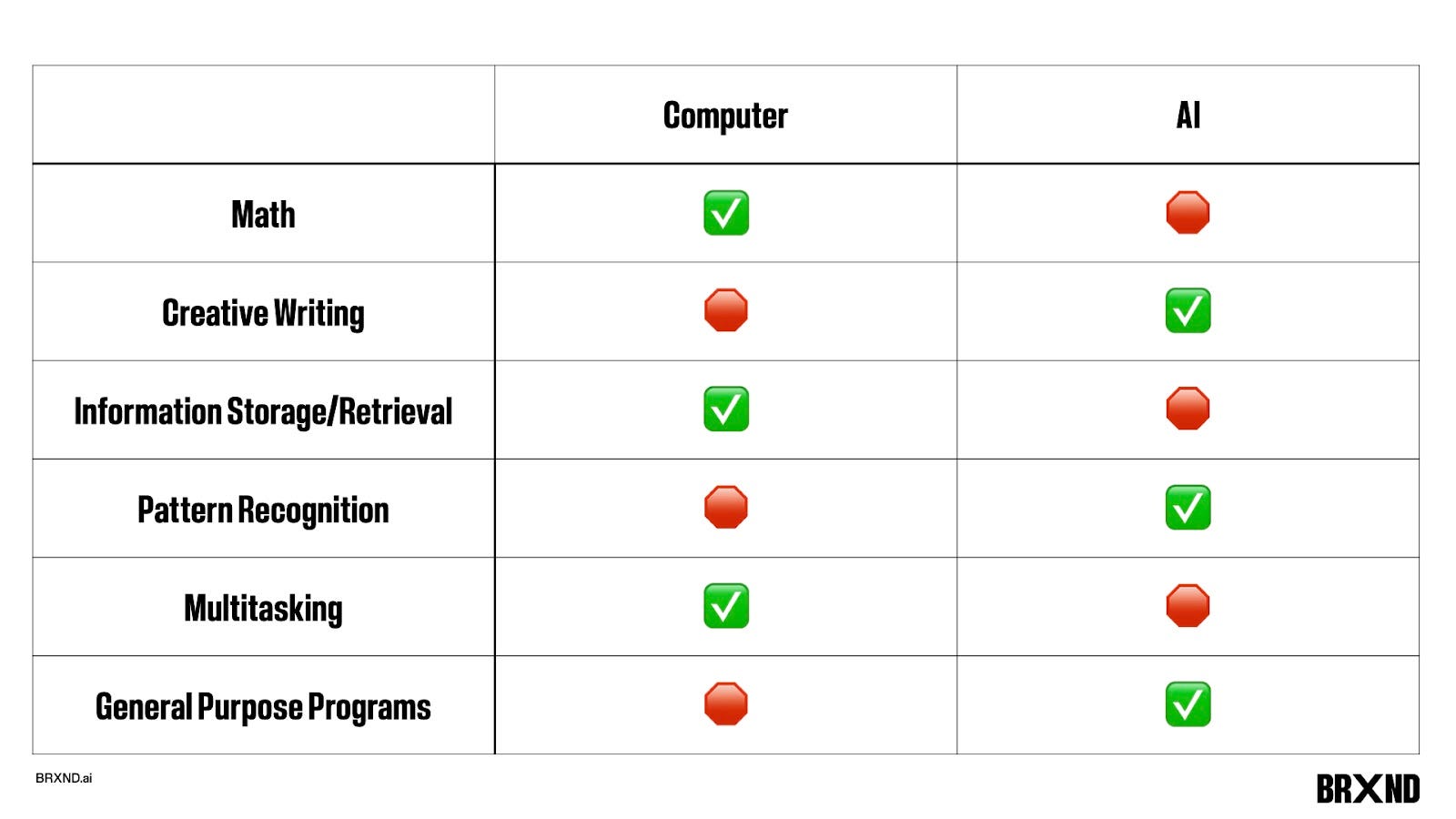
Why is this interesting?
Given this, Tim went on to explain just how odd it is that the industry heavyweights have decided to apply this tech to search first:
It’s in some ways kind of an absurdity—an incredible colossal irony—that the very first product that Silicon Valley wanted to apply this technology towards is search. So BARD is the future of Google search, and Bing chat is the future of the Bing search engine. But ultimately, these technologies are not good at facts; they're not good at logic. All of these things are what you use search engines for. And, in fact, there's actually a huge kind of rush right now in the industry where everybody has rushed into implementing this technology and been like, “This is really bad.” And basically, what everybody's doing right now is trying to reconstruct what they call retrieval or factuality in these technologies. The point here is that large language models need factuality as an aftermarket add-on. It isn't inherent to the technology itself.
The reason for that, as Tim eloquently articulated, is that “LLMs are concept retrieval systems, not fact retrieval systems.”
To that end, the rest of the talk explores how to take better advantage of this “concept retrieval” power and what kind of UX might better match the system’s strengths. Here’s the full video:
—
Thanks for reading,
Noah (NRB) & Colin (CJN)
—
Why is this interesting? is a daily email from Noah Brier & Colin Nagy (and friends!) about interesting things. If you’ve enjoyed this edition, please consider forwarding it to a friend. If you’re reading it for the first time, consider subscribing.
Fascinating and so well-explained. Reminds me of conversations around cloning - if there’s a version of you but it didn’t actually go through what you did, could it still be you etc